ℹ️注意
- 本記事の内容は、ゲーム攻略にはほとんど価値がないと思います。純粋な興味と、調査にあたって要した技術的知見のメモが目的です。
- 本記事にはゲーム中のスクリーンショットが含まれます。以下ガイドラインに沿います。https://www.gamecity.ne.jp/info/videopolicy.html
遠征に関する記事はこちら:
先に結論・成果物
石高算出式
対象エリアの面積[㎡]をとして、石高
は、
※私が調査した範囲での石高・面積からの回帰分析による結果であり、誤差があろうかと思います。小数点以下は四捨五入したのが実際の値と推測します。
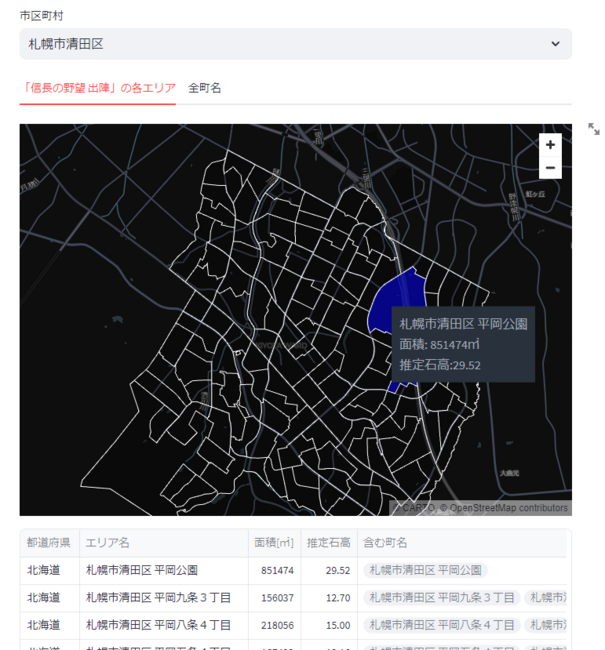
Streamlit
各エリアを地図上にプロットしました。石高・面積も見られます。手作業なので少ししかありませんが。
nobunaga-area-map.streamlit.app
背景
「信長の野望 出陣」は、2023年8月31日にリリースされた位置情報ゲームです。
www.gamecity.ne.jp 歴代作品同様に領地を広げるのが1つの目標ですが、攻め取るには実際に日本全国の町丁*1を基準に設置されている「拠点」を訪れる必要があります*2。
今回のネタ
「エリアごとの石高はどのように決まっているのか?」
拠点ごとの領域(領地)を本記事では「エリア」と呼ぶことにします。プレイしていれば誰しも気付くはずですが、以下の特徴があります。
- エリアごとに石高が定められていて、広いエリアほど石高が多い。
- 1つのエリアは、1つまたは複数の町丁で構成されている。
- 最低でも1エリアあたり10石以上になるよう区分けされている模様。
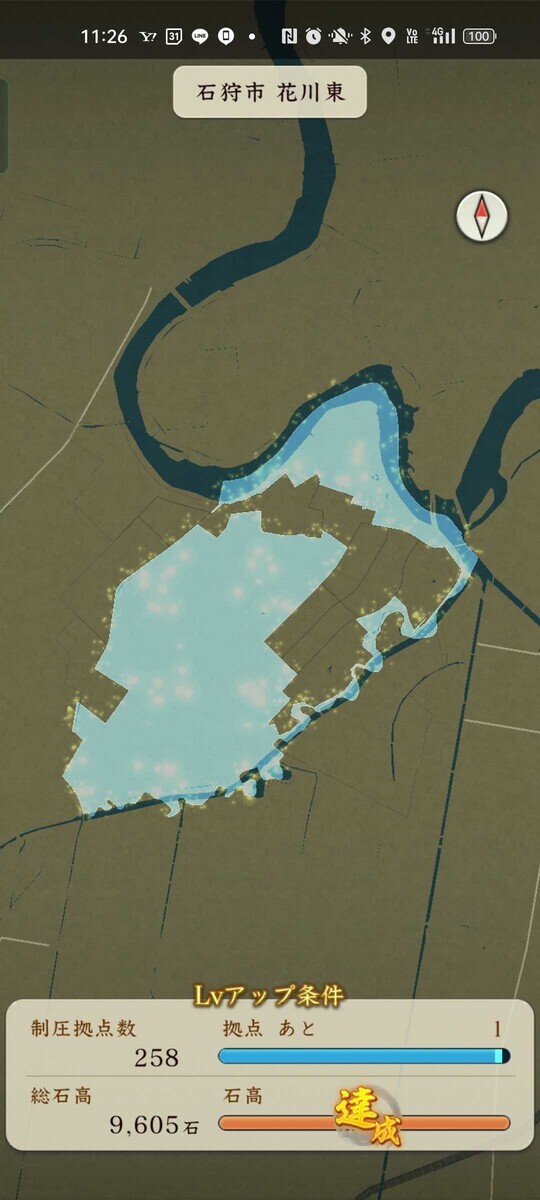
以下の画像の例では、左は「札幌市厚別区上野幌二条2丁目」と「同 上野幌二条3丁目」の2つを合わせて1エリアとなっています。右は「江別市江別太」が広大なため、単独で1エリアとなっているようです。
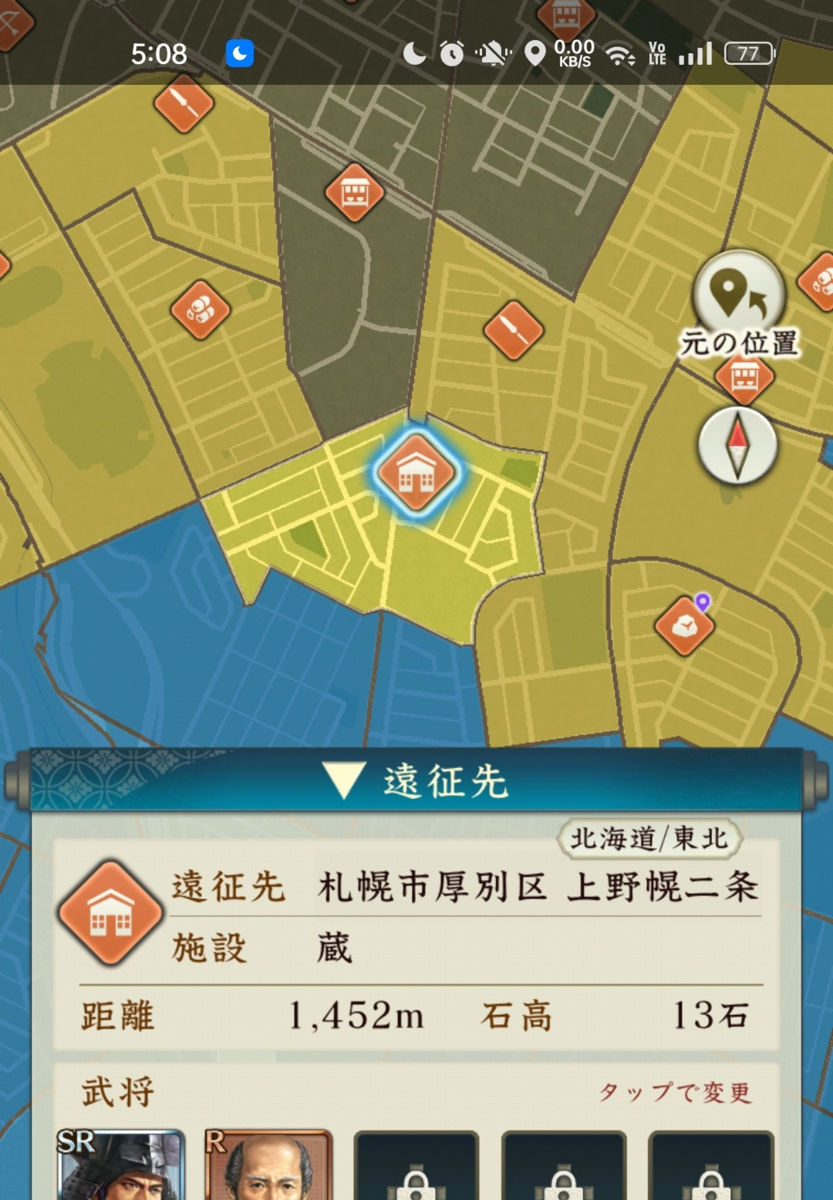

ここで上記の疑問が出てきました。エリアごとの石高はどのように決まっているのでしょうか?
環境・確認バージョン
streamlit==1.26.0 shapely==2.0.1 more-itertools==10.1.0 pydantic==2.3.0
石高の法則を見出す
石高のサンプルを集める
エリアと石高の対応サンプルを集めて、法則性を見出してみましょう。さてここで大きな課題があります(バージョン1.01.0.57774時点)。
- 石高がわかるのは、エリア獲得時、または遠征時(自分の領地に隣接するエリア)のみ。
- 既に領有してしまったエリアや、はるか離れたエリアは自分ではわからない。
- (本拠地・支城移転時にはエリア名確認はできそう)
ゲーム中の地図では、各エリアの境界線しかわからず、石高はおろかエリア名 (町名) も再参照不能です。
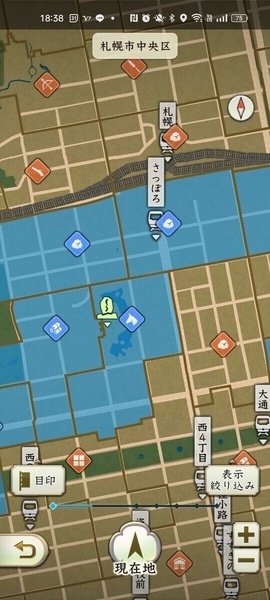
つまり、エリア獲得戦の勝利時または遠征先選択時に忘れずにメモしておくしかありません。私はこれに気づいて以降、エリア獲得の度にほぼ欠かさずスクリーンショットを撮り続けました。札幌近郊に限られますが結構なサンプル数が集まってきました。

この画面はそれぞれ3秒程度しか表示されず、ボーっとしていると流れてしまいます。誤タップでスキップしてしまうこともあります。時々撮り漏らしています。
エリアごとの面積を知る
石高と広さに何らか相関があるはずと見立て、次は具体的な面積を集めに行きます。
機能→その他→各種表記→権利表記 から、本ゲームが参照したデータや利用ライブラリを一覧できます。利用許諾契約等と異なりWeb上には見当たらないため、スクリーンショットで示します。
ここからe-Statのサイトを参照したであろうことがわかるので、同じく見に行き、「経済センサス-活動調査」を参照しました。ファイル形式を選べますが、「GML」としました。地域は北海道にします。
GMLはGeography Markup Languageを意味し、XMLです。各フィールドの仕様はe-Statにある定義書から確認できます。GML仕様や定義書の内容をもし知らなくても、少しGMLファイルの中身を読めばすぐ雰囲気はつかめるはずです。
<!-- 今回必要なフィールドのみ抜粋 --> <?xml version="1.0" encoding="UTF-8"?> <gml:FeatureCollection xmlns:fme=...> <gml:boundedBy> ... </gml:boundedBy> <gml:featureMember> <fme:h28ca01 gml:id="id0"> <fme:PREF_NAME>北海道</fme:PREF_NAME> <fme:CITY_NAME>札幌市中央区</fme:CITY_NAME> <fme:S_NAME>旭ケ丘1丁目</fme:S_NAME> <fme:AREA>54322.020</fme:AREA> <gml:surfaceProperty> <gml:Surface srsName="EPSG:4612" srsDimension="2"> <gml:patches> <gml:PolygonPatch> <gml:exterior> <gml:LinearRing> <gml:posList>43.0439048363 141.3196243134 43.0434857813 141.3196809857 ... </gml:posList> </gml:LinearRing> </gml:exterior> </gml:PolygonPatch> </gml:patches> </gml:Surface> </gml:surfaceProperty> </fme:h28ca01> </gml:featureMember> <gml:featureMember> . . . </gml:featureMember> </gml:FeatureCollection>
とりあえずは欲しい面積の値は <fme:AREA> の箇所に平方メートル単位で書かれています。この旭ケ丘1丁目の例では54322.020㎡です。
石高と面積を集計
私が知るエリアのうち、広いものを中心にまとめました。街中の10石台のエリアはあまり載せていません。
回帰分析
続いてこれをグラフにします。「散布図」を選び、面積と石高を軸として選びます。Googleスプレッドシートの場合、系列の設定にてトレンドラインを表示できます。方程式を表示するようにします。
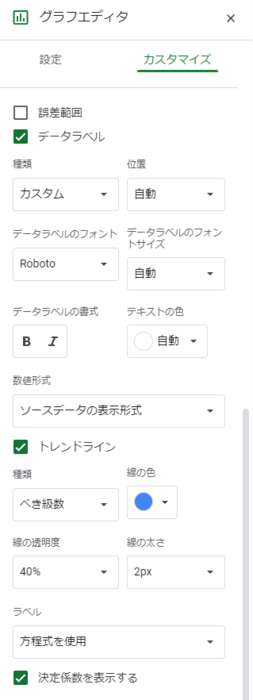
すると今回はこのようなグラフになりました。トレンドラインは「べき級数」が非常によく合致します。表示されている決定係数 R2 は1に近いほどよく近似できているわけですが、いきなり1をたたき出しています。ですから多分これで正解でしょう。ここからのフィッティングに難航するかと思いきや、あっけなく話が終わってしまいました。
ところで、札幌近郊の中では圧倒的面積を誇る*3「札幌市南区 定山渓」という区域がありまして、それをグラフに含めると以下のようになります。急に縮尺が激変してしまいますが、これでもトレンドライン上でほぼ近似できていますね。
以上で、労せずして回帰分析にだいたい成功したわけですが、特に面積が巨大になってくるにつれ石高が低い方に微妙にずれています。考えられる誤差の要因は以下です。
- データの誤り
- 複数町丁の合体エリアで取り漏らし多発。ここまでだけでも数時間は地図とにらめっこしています。
- 石高が整数値(離散値)である制約
- 「15.6石」のような小数が現れないため、特に面積が小さいエリアでは誤差が響いてしまいます。
石高が30石未満のエリアをデータから外してみると、以下の式となります。
実装でこんな中途半端な係数を使うかな?と思うので、実際は記事冒頭で述べたような以下のようになっている気がしています。*4
可視化
ここからは、pydeck (deck.gl) によって地図上に石高付きでエリアをプロットしていきます。
PolygonLayer を使います。PolygonLayer — pydeck 0.8.0b4 documentation
GMLを解釈しpandas.DataFrameに変換
上記PolygonLayerのサンプルコードを見ると分かるように、pydeckのLayerにはpandasのDataFrameと、どの列が緯度経度なのか、の2つを渡せば、それだけで輪郭を描いてくれます。よってGMLを読んでDataFrameとして詰め込んでいきます。
PythonでGMLすなわちXMLを読むため、xml.etree.ElementTree を使います。入力ファイルはe-Statから入手したZIPファイルそのものとします*5。以下の記事が参考になりました。 docs.python.org tm23forest.com
import more_itertools import zipfile from xml.etree import ElementTree NAMESPACES = { "gml": "http://www.opengis.net/gml", "fme": "http://www.safe.com/gml/fme", "xsi": "http://www.w3.org/2001/XMLSchema-instance", "xlink": "http://www.w3.org/1999/xlink" } def load_data_from_gml_zip(file_name: str) -> pd.DataFrame: with zipfile.ZipFile(file_name, 'r') as zf: # ZIPにはファイルが2個入っており、GMLの方を選択 gml_file_name = more_itertools.first_true(zf.namelist(), pred=lambda f: splitext(f)[1] == ".gml") with zf.open(gml_file_name, 'r') as file: tree = ElementTree.parse(file) return load_data(tree) def load_data(tree: ElementTree) -> pd.DataFrame: prefecture_names: list[str] = [] city_names: list[str] = [] addresses: list[str] = [] areas: list[float] = [] lonlat_lists: list[list[list[list[float]]]] = [] for feature_member in tree.findall("gml:featureMember", NAMESPACES): elem = feature_member[0] prefecture_names.append(elem.find("fme:PREF_NAME", NAMESPACES).text) city_name = elem.find("fme:CITY_NAME", NAMESPACES).text town_name = elem.find("fme:S_NAME", NAMESPACES).text city_names.append(city_name) addresses.append(f"{city_name} {town_name}") areas.append(float(elem.find("fme:AREA", NAMESPACES).text)) pos_list_elem = elem.find("gml:surfaceProperty//gml:Surface//gml:PolygonPatch//gml:exterior//gml:LinearRing//gml:posList", NAMESPACES) pos_list = [float(v) for v in pos_list_elem.text.split(" ")] lonlat_list = [[[pos_list[i*2+1], pos_list[i*2]] for i in range(len(pos_list) // 2)]] lonlat_lists.append(lonlat_list) data = { "prefecture_name": prefecture_names, "city_name": city_names, "address": addresses, "area": areas, "lonlat_coordinates": lonlat_lists, } return pd.DataFrame( data=data, columns=data.keys() ) df = load_data_from_gml_zip("input.zip")
町丁をエリアとして再編・石高の算出
e-Statのデータは現実の町丁単位の座標・面積が書かれており、当然ながら「信長の野望 出陣」 のエリア定義と差があります。エリアは1つまたは複数の町丁で構成されますから、複数で構成の場合は各町丁をマージするような処理が必要です。
まずエリアの定義ファイルをJSONで書くことにします。前述のように、私のスクショや地図からの分析だけが頼りです。エリア名 (複数町丁のうちの代表名)と、エリアを構成する各町丁の名前を列挙していきます。*6
{ "札幌市清田区 平岡公園": [ "札幌市清田区 平岡公園" ], "札幌市清田区 平岡九条3丁目": [ "札幌市清田区 平岡九条3丁目", "札幌市清田区 平岡九条4丁目", "札幌市清田区 平岡十条3丁目" ], "札幌市清田区 平岡八条4丁目": [ "札幌市清田区 平岡八条4丁目", "札幌市清田区 平岡七条4丁目", "札幌市清田区 平岡六条4丁目" ], "札幌市清田区 平岡五条4丁目": [ "札幌市清田区 平岡五条4丁目", "札幌市清田区 平岡五条6丁目" ], "札幌市清田区 平岡四条6丁目": [ "札幌市清田区 平岡四条6丁目" ], ... }
このJSONを読み込みつつ、先ほど作ったDataFrameを改変していきます。
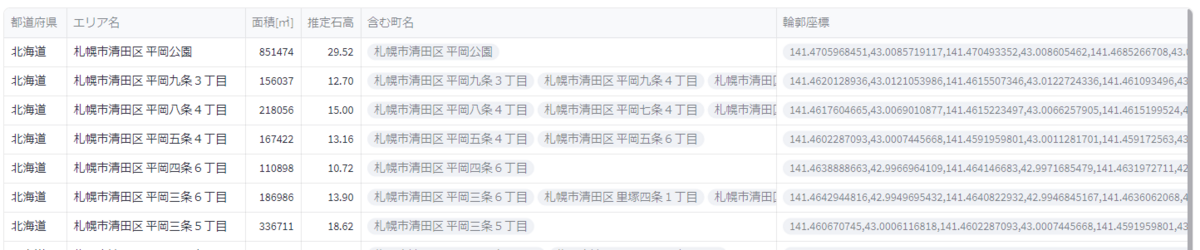
def mod_data(df: pd.DataFrame, correspondences: dict[str, list[str]]) -> pd.DataFrame: new_data = { "prefecture_name": [], "address": [], "area": [], "kokudaka": [], "sub_addresses": [], "lonlat_coordinates": [], } for address, sub_addresses in correspondences.items(): sub_rows = df.query("address in @sub_addresses") prefecture_name = sub_rows.iloc[0]["prefecture_name"] area: float = sub_rows["area"].sum() kokudaka = estimate_kokudaka(area) # st.write(new_data["address"][-1], sub_rows) polygons = [shapely.geometry.Polygon(c[0]) for c in sub_rows["lonlat_coordinates"].values] if not polygons: new_data["lonlat_coordinates"].append([]) continue merged_polygon = functools.reduce(lambda r, s: r.union(s), polygons[1:], polygons[0]) if merged_polygon.geom_type == "Polygon": coords = [list(merged_polygon.exterior.coords)] elif merged_polygon.geom_type == "MultiPolygon": coords = [list(p.exterior.coords) for p in merged_polygon.geoms] # st.write(new_data["address"][-1], coords) else: raise if len(coords) > 1: address += " (飛び地あり)" for c in coords: new_data["prefecture_name"].append(prefecture_name) new_data["address"].append(address) new_data["area"].append(round(area)) new_data["kokudaka"].append(round(kokudaka, 2)) new_data["sub_addresses"].append(sub_addresses) new_data["lonlat_coordinates"].append([c]) return pd.DataFrame( data=new_data, columns=new_data.keys() ) def estimate_kokudaka(area: float) -> float: return (area ** 0.497) / 30 import json with open("correspondences.json") as f: correspondences = json.load(f) df_mod = mod_data(df, correspondences)
これでDataFrameは以下のようになりました。
町丁には飛び地が存在する場合があります。一例: 北海道札幌市中央区宮の森 - Yahoo!マップ
飛び地については「信長の野望 出陣」としては同一エリアとして扱っているようですが、e-StatのGMLでは飛び地単位で個別の行になっており、輪郭や面積は合算してあげる必要があります。輪郭のマージについては以下の記事で過去扱いました。
ただし後述するpydeck.Polygonlayerへの描画にあたっては、PolygonLayerは飛び地の描画 (ハイライト) に対応しないらしく微妙な挙動になるため、DataFrameとしてはGML通りに個別の行で持つようにしています。
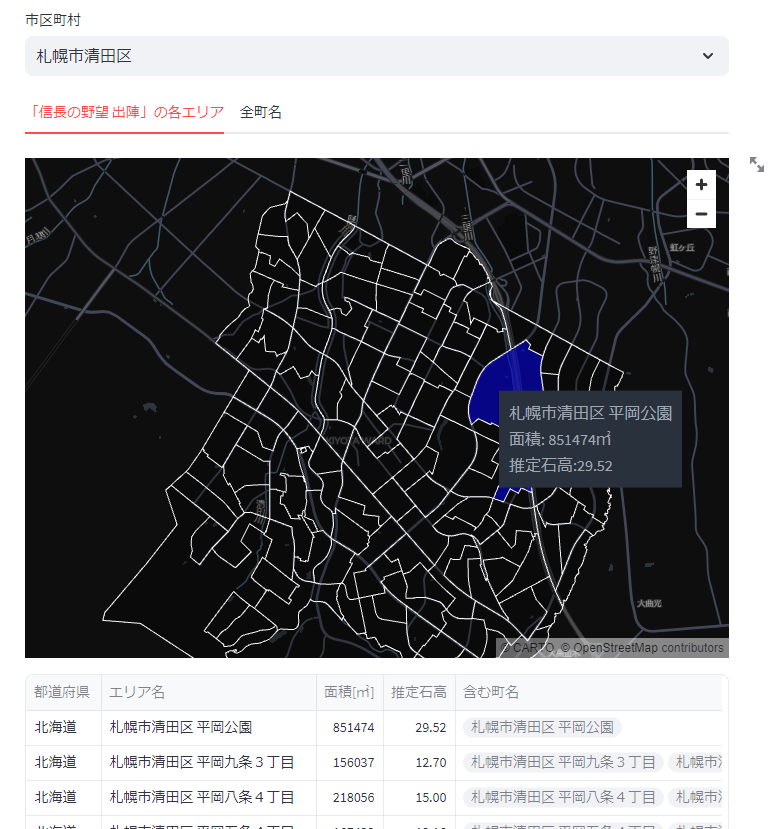
pydeck.PolygonLayerにDataFrameを描画
PolygonLayerにDataFrameを指定します。今回はpydeckの表示にはStreamlitを使いました。
polygon_layer = pydeck.Layer(
"PolygonLayer",
df,
stroked=True,
filled=True,
extruded=False,
wireframe=True,
line_width_scale=10,
line_width_min_pixels=1,
get_polygon="lonlat_coordinates",
get_line_color=[255, 255, 255],
get_fill_color=[0, 0, 0, 64],
highlight_color=[0, 0, 255, 128],
auto_highlight=True,
pickable=True,
)
deck = pydeck.Deck(
layers=(polygon_layer, ),
initial_view_state=pydeck.ViewState(
latitude=42.995,
longitude=141.450,
zoom=11.5,
max_zoom=16,
pitch=0,
bearing=0),
tooltip={"text": "{address}\n面積: {area}㎡\n推定石高:{kokudaka}"}
)
st.pydeck_chart(deck)
その他雑感
複数の町丁を合わせて1エリアとする基準
おそらく10石を下回るエリアがないのはプレイされた方には共通認識としてあるはずで、狭い町丁の場合は複数くっつけて1エリアとなっているわけです。ところが、広大なのに複数町丁で構成されるケースも存在します。
支笏湖南岸にある千歳市「支寒内(ししゃもない)」は、単独で100石を超えるはずの広い領域ですが、東隣の「モラップ」とあわせて1エリアとなっています。推測ですが、あまりに山中で徒歩での到達は(一般人には)困難で、車で通って停車することすら難しそうです。ゆえに合併されたのかもしれません。(とはいえ隣のモラップもその点大差ない気はしつつ。)


また別の例として、上の方でも例示した「花川東」も、実は「緑苑台西二条3丁目」を含みます。ここについては、「花川東」自体は市街化調整区域(っぽい)ものの市街地に近く、十分到達可能です。しかしながら、相方の「緑苑台西二条3丁目」のほうが狭くかつ割と到達困難ということで合併されたと思われます。

こんな感じで、プレイに支障が無いよう考えてエリアの区分けがされているのではなかろうかと考えます。クローズドベータテストを事前に行っていたのも、このへんの課題を事前に洗い出す目的があったのかもしれません。
*1:「東京都千代田区 "九段南4丁目"」のような、市区町村の下に置かれる行政区画を指します。
*2:遠征もできます。
*3:日本全国でも第6位。ちなみにおそらく第1位は北海道新得町の「屈足」(経済センサスデータだと「字トムラウシ」)です: https://maps.app.goo.gl/nyQLtjVokiwoumBd6
*4:指数の0.497も実際は0.5なのでは、と思いましたが、そうしてみるとずれが大きくなります。
*5:事前に解凍するとファイルサイズが大きく、GitHubに置きがたいため。
*6:エリア名とすべき町名がどれなのかもスクショに頼るほかなく、不明の場合は適当に決めています。